Hello! This article will illustrate the result of applying some important and exotic HTTP headers, most of which are related to security.
X-XSS-Protection
Attack XSS (cross-site scripting) is a type of attack in which malicious code can be embedded in the target page.
For example like this:
<h1>Hello, <script>alert('hacked')</script></h1>This type of attacks easy to detect and the browser may handle it: if the source code contains part of the request, it may be a threat.
And the title X-XSS-Protection manages the behavior of the browser.
Accepted values:
- 0 the filter is turned off
- 1 filter is enabled. If the attack is detected, the browser will remove the malicious code.
- 1; mode=block. The filter is enabled, but if the attack is detected, the page will not be loaded by the browser.
- 1; report=http://domain/url. the filter is enabled and the browser will clear the page from malicious code while reporting the attempted attack. Here, we use a function Chromium for reporting violation of content security policy (CSP) to a specific address.
Create a web server sandbox on node.js to see how it works.
var express = require('express')
var app = express()
app.use((req, res) => {
if (req.query.xss) res.setHeader('X-XSS-Protection', req.query.xss)
res.send(`<h1>Hello, ${req.query.user || 'anonymous'}</h1>`)
})
app.listen(1234)
I will use Google Chrome 55.
No title
http://localhost:1234/?user=%3Cscript%3Ealert(%27hacked%27)%3C/script%3E
Nothing happens, the browser will successfully block the attack. Chrome, by default, blocks the threat and reported it to the console.

It even highlights the problem area in the source code.

X-XSS-Protection: 0
http://localhost:1234/?user=%3Cscript%3Ealert(%27hacked%27)%3C/script%3E&xss=0
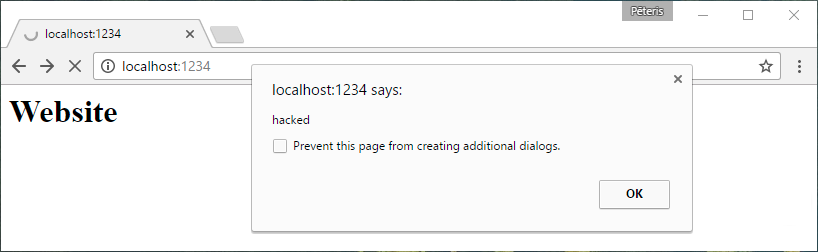
Oh no!
X-XSS-Protection: 1
http://localhost:1234/?user=%3Cscript%3Ealert(%27hacked%27)%3C/script%3E&xss=1
Page was cleared because of the explicit title.0
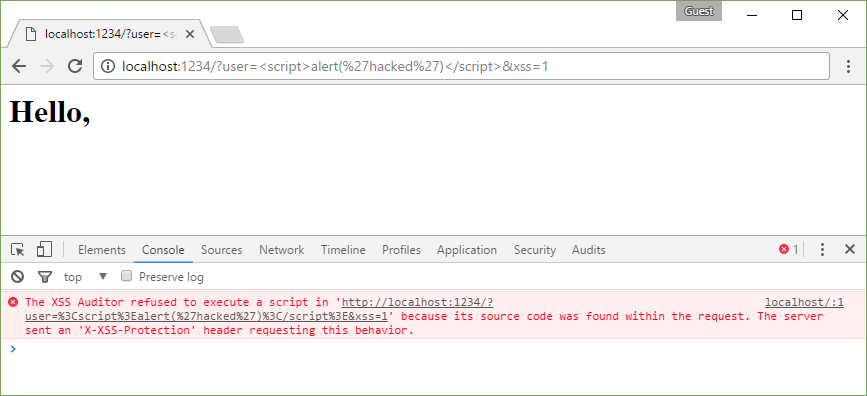
X-XSS-Protection: 1; mode=block
http://localhost:1234/?user=%3Cscript%3Ealert(%27hacked%27)%3C/script%3E&xss=1;%20mode=block
In this case, the attack will be prevented by blocking the page load.
X-XSS-Protection: 1; report=http://localhost:1234/report
http://localhost:1234/?user=%3Cscript%3Ealert(%27hacked%27)%3C/script%3E&xss=1;%20report=http://localhost:1234/report
The attack is prevented and a message is sent to the appropriate address.

X-Frame-Options
With this title you can protect yourself from the so-called Clickjacking.
Imagine that the attacker has a channel on YouTube and he wants more followers.
He can create a page with a button “Do not press”, which would mean that everyone will click on it necessarily. But over the button is completely transparent iframe and in this frame hides the channel page with the subscription button. Therefore, when you press the button, in fact, a user subscribes to a channel, unless of course, he was logged into YouTube.
We will demonstrate that.
First, you need to install the extension to ignore this header.
Create a simple page.
<style>
button { background: red; color: white; padding: 10px 20px; border: none; cursor: pointer; }
iframe { opacity: 0.8; z-index: 1; position: absolute; top: -570px; left: -80px; width: 500px; height: 650px; }</style>
<button>Do not click his button!</button>
<iframe src="https://youtu.be/dQw4w9WgXcQ?t=3m33s"></iframe>
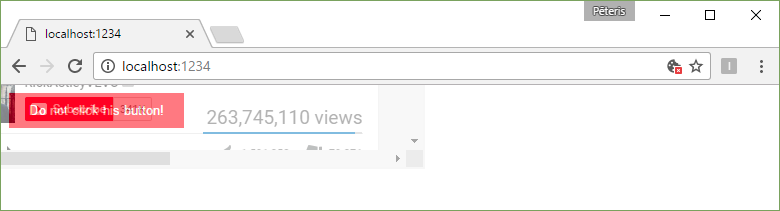
As you can see, I have placed the frame with the subscription right over the button (z-index: 1) and so if you try to click it, you actually press the frame. In this example, the frame is not fully transparent, but it can be fixed with the value of opacity: 0.
In practice, this doesn’t work, because YouTube set the desired heading, but the sense of threat, I hope, is clear.
To prevent the page to be used in the frame need to use the title X-Frame-Options.
Accepted values:
- deny not load the page at all.
- sameorigin not load if the source is not the same.
- allow-from: DOMAIN you can specify the domain from which the page can be loaded in a frame.
We need a web server to demonstrate
var express = require('express')
for (let port of [1234, 4321]) {
var app = express()
app.use('/iframe', (req, res) => res.send(`<h1>iframe</h1><iframe src="//localhost:1234?h=${req.query.h || ''}"></iframe>`))
app.use((req, res) => {
if (req.query.h) res.setHeader('X-Frame-Options', req.query.h)
res.send('<h1>Website</h1>')
})
app.listen(port)
}
No title
Everyone will be able to build our website on localhost:1234 in the frame.

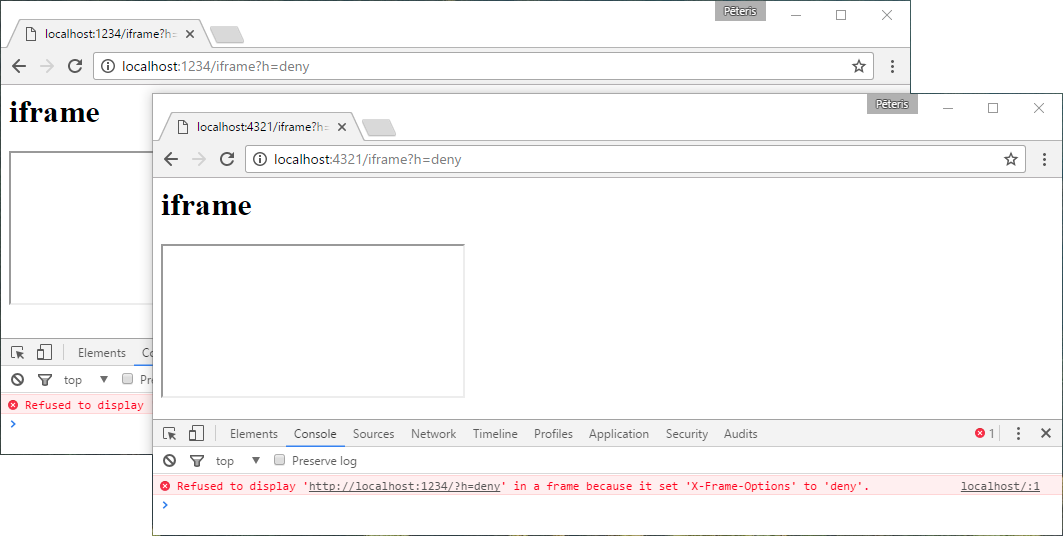
X-Frame-Options: deny
The page cannot be used at all in the frame.
X-Frame-Options: sameorigin
Only pages with the same source will be able to be built into the frame. The sources are the same, if the domain, port and protocol are the same.
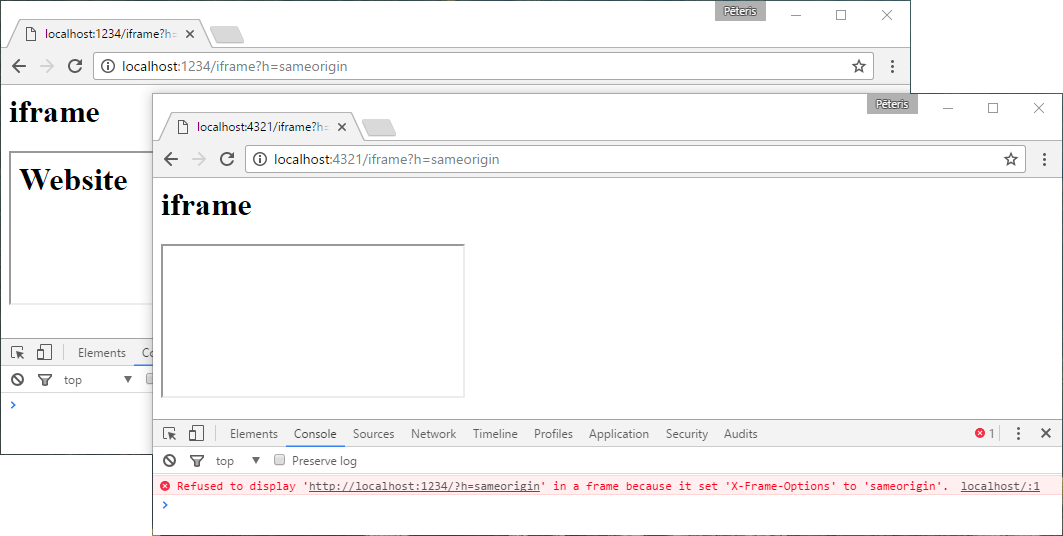
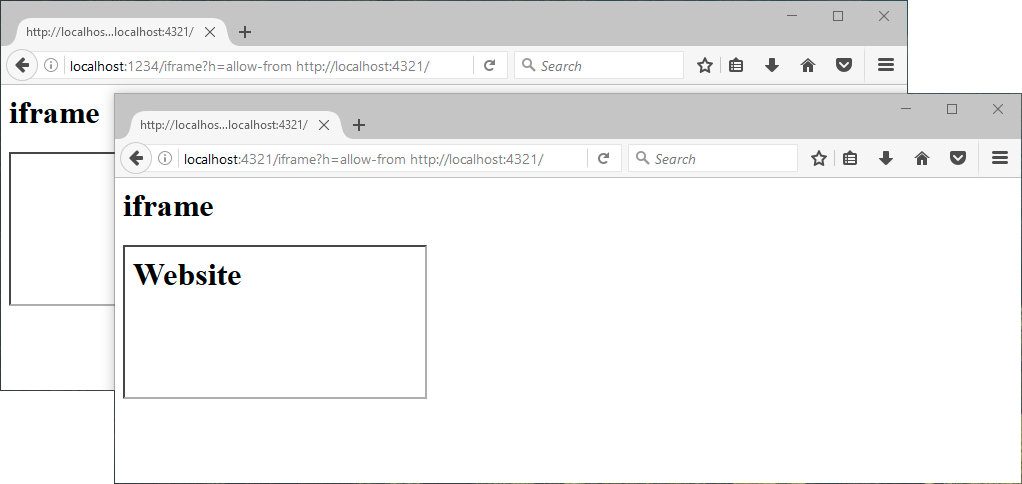
X-Frame-Options: allow-from localhost:4321
It seems that Chrome ignores this option, because there is a header Content-Security-Policy (about it will be discussed below). It does not work in Microsoft Edge.
Below Mozilla Firefox.
X-Content-Type-Options
This header prevents attacks spoofing MIME type (<script src=”script.txt”>) or unauthorized hotlinking (<script src=”https://raw.githubusercontent.com/user/repo/branch/file.js”>)
var express = require('express')
var app = express()
app.use('/script.txt', (req, res) => {
if (req.query.h) res.header('X-Content-Type-Options', req.query.h)
res.header('content-type', 'text/plain')
res.send('alert("hacked")')
})
app.use((req, res) => {
res.send(`<h1>Website</h1><script src="/script.txt?h=${req.query.h || ''}"></script>`
})
app.listen(1234)
No title
http://localhost:1234/
Though script.txt is a text file with type text/plain, it will be launched as a script.
X-Content-Type-Options: nosniff
http://localhost:1234/?h=nosniff
This time the types do not match and the file will not be executed.

Content-Security-Policy
It is a relatively new title and helps to reduce the risks of XSS attacks in modern browsers by specifying in the title what resources can be loaded on the page.
For example, you can ask the browser do not execute inline-scripts and download files only from one domain. Inline-scripts can look not only like <script>…</script>, but also as <h1 onclick=”…”>.
Let’s see how it works.
var request = require('request')
var express = require('express')
for (let port of [1234, 4321]) {
var app = express()
app.use('/script.js', (req, res) => {
res.send(`document.querySelector('#${req.query.id}').innerHTML = 'changed ${req.query.id}-script'`)
})
app.use((req, res) => {
var csp = req.query.csp
if (csp) res.header('Content-Security-Policy', csp)
res.send(`
<html>
<body>
<h1>Hello, ${req.query.user || 'anonymous'}</h1>
<p id="inline">this will changed inline-script?</p>
<p id="origin">this will changed origin-script?</p>
<p id="remote">this will changed remote-script?</p>
<script>document.querySelector('#inline').innerHTML = 'changed inline-script'</script>
<script src="/script.js?id=origin"></script>
<script src="//localhost:1234/script.js?id=remote"></script>
</body>
</html>
`)
})
app.listen(port)
}
No title
It works as you would expect
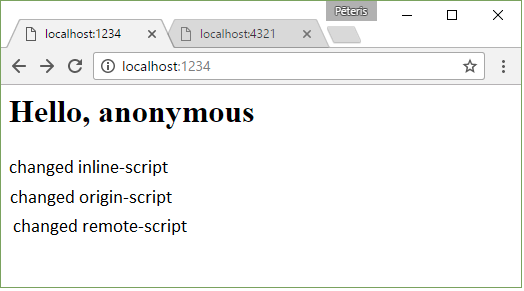
Content-Security-Policy: default-src ‘none’
http://localhost:4321/?csp=default-src%20%27none%27&user=%3Cscript%3Ealert(%27hacked%27)%3C/script%3E
default-src applies a rule to all resources (images, scripts, frames, etc.), the value ‘none’ disables all. Below is shown what happens and the errors displayed in the browser.
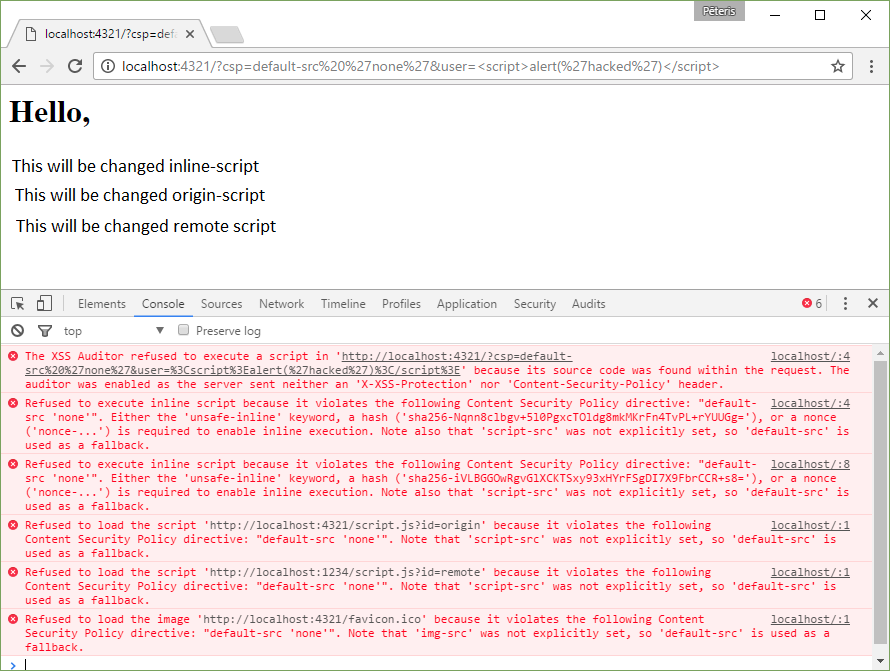
Chrome refused to run any scripts. In this case, you can’t even upload a favicon.ico.
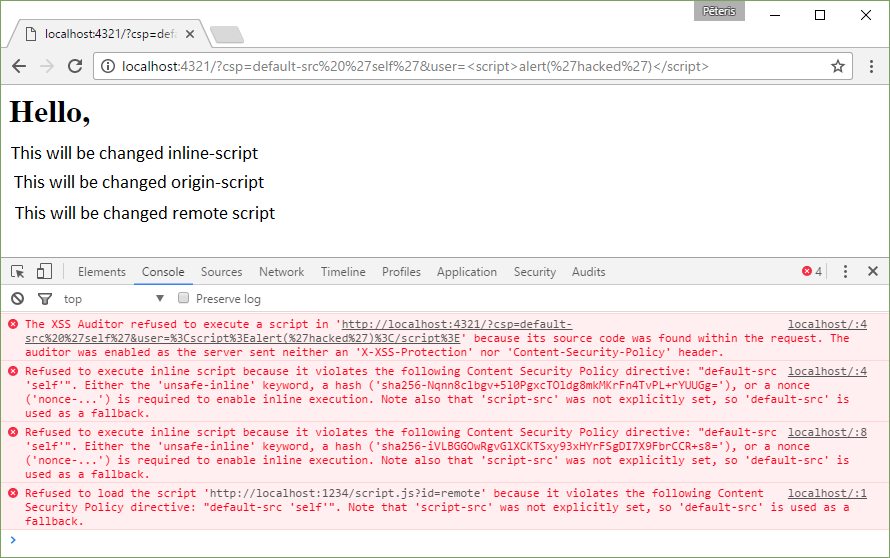
Content-Security-Policy: default-src ‘self’
http://localhost:4321/?csp=default-src%20%27self%27&user=%3Cscript%3Ealert(%27hacked%27)%3C/script%3E
Now it is possible to use the resources from one source but still cannot run external and inline-scripts.
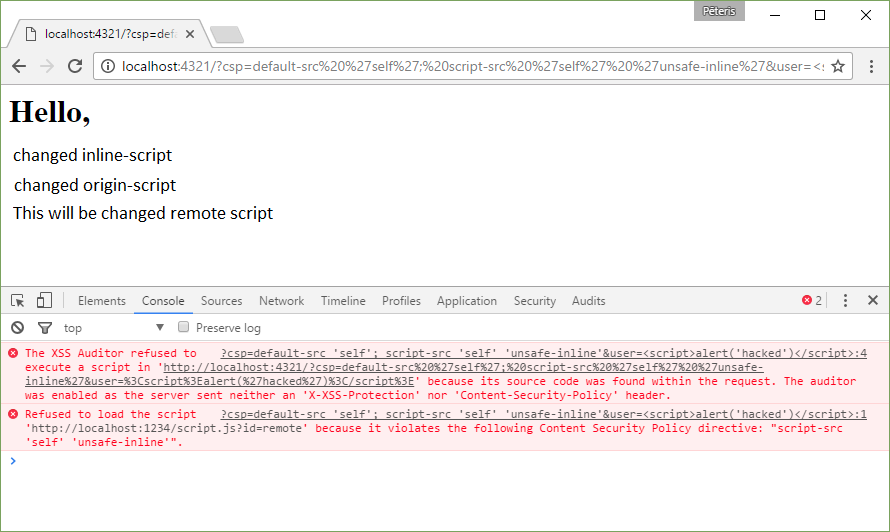
Content-Security-Policy: default-src ‘self’; script-src ‘self’ ‘unsafe-inline’
http://localhost:4321/?csp=default-src%20%27self%27;%20script-src%20%27self%27%20%27unsafe-inline%27&user=%3Cscript%3Ealert(%27hacked%27)%3C/script%3E
This time we let the execution and inline-scripts. Please note that XSS attack in the request was blocked too. But this will not happen if at the same time deliver and unsafe-inline and X-XSS-Protection: 0.
Other values
On the website, content-security-policy.com beautifully had shown many examples.
- default-src ‘self’ allowed resources only from one source
- script-src ‘self’ www.google-analytics.com ajax.googleapis.com allow Google Analytics, Google AJAX CDN, and resources from one source.
- default-src ‘none’; script-src ‘self’; connect-src ‘self’; img-src ‘self’; style-src ‘self’; allow images, scripts, AJAX and CSS from one source and prohibit the downloading of any other resources. For most sites this is a good initial setting.
I didn’t check, but I think that the following headers are equivalent:
- frame-ancestors ‘none’ and X-Frame-Options: deny
- frame-ancestors ‘self’ and X-Frame-Options: sameorigin
- frame-ancestors localhost:4321 and X-Frame-Options: allow-from localhost:4321
- script-src ‘self’ without ‘unsafe-inline’ and X-XSS-Protection: 1
If you look at the headers facebook.com or twitter.com it is possible to notice that these sites use a lot of CSP.
Strict-Transport-Security
HTTP Strict Transport Security (HSTS) is a mechanism for security policy, which helps protect the website from attempts by an unsecured connection.
Let’s say that we want to connect to facebook.com. If you don’t specify before requesting https://, protocol, by default, will be selected HTTP and therefore the request will look like http://facebook.com.
$ curl -I facebook.com
HTTP/1.1 301 Moved Permanently
Location: https://facebook.com/
After that, we will be redirected to the secure version of Facebook.
If you connect to a public WiFi hotspot, which is owned by the attacker, the request may be intercepted and instead facebook.com the attacker may substitute a similar page to know the username and password.
To guard against such an attack, you can use the aforementioned title that will tell the client the next time to use the https-version of the site.
$ curl -I https://www.facebook.com/
HTTP/1.1 200 OK
Strict-Transport-Security: max-age=15552000; preload
If the user was logged into Facebook at home and then tried to open it from an unsafe access point, he is not in danger, because browsers remember the title.
But what happens if you connect to the unsecured network first time? In this case, the protection will not work.
But browsers have a trump card in this case. They have a predefined list of domains for which should be used HTTPS only.
You can send your domain at this address. It is also possible to find out whether the header is used correctly.
Accepted values:
- max-age=15552000 the time in seconds that the browser should remember the title.
- includeSubDomains If you specify this optional value, the header applies to all subdomains.
- preload if the site owner wants the domain got into a predefined list that is supported by Chrome (and used by Firefox and Safari).
And if you need to switch to HTTP before the expiration of max-age or if you set preload? You can put the value max-age value=0 and then the navigation rule to the https version will stop to work.
Public-Key-Pins
HTTP Public Key Pinning (HPKP) is a mechanism for security policy that allows HTTPS sites to protect against malicious use of fake or fraudulent certificates.
Accepted values:
- pin-sha256=”<sha256>” in quotes is encoded using Base64 thumbprint of the Subject Public Key Information (SPKI). You can specify multiple pins for different public keys. Some browsers in the future may use other hashing algorithms besides SHA-256.
- max-age=<seconds> the time, in seconds, that for access to the site need to use only the listed keys.
- includeSubDomains if you specify this optional parameter, the title applies to all subdomains.
- report-uri=”<URL>” if you specify URL, then when a validation error key, the corresponding message will be sent to the specified address.
Instead of the title Public-Key-Pins, you can use Public-Key-Pins-Report-Only, in this case, it will only send the error messages to match the keys, but the browser will still load the page.
So does Facebook:
$ curl -I https://www.facebook.com/
HTTP/1.1 200 OK
...
Public-Key-Pins-Report-Only:
max-age=500;
pin-sha256="WoiWRyIOVNa9ihaBciRSC7XHjliYS9VwUGOIud4PB18=";
pin-sha256="r/mIkG3eEpVdm+u/ko/cwxzOMo1bk4TyHIlByibiA5E=";
pin-sha256="q4PO2G2cbkZhZ82+JgmRUyGMoAeozA+BSXVXQWB8XWQ=";
report-uri="http://reports.fb.com/hpkp/"
Why is it necessary? Not enough of trusted certification authorities (CA)?
An attacker can create a certificate for facebook.com and by tricking the user to add it to your list of trusted certificates, or it can be an administrator.
Let’s try to create a certificate for facebook.
sudo mkdir /etc/certs
echo -e 'US\nCA\nSF\nFB\nXX\nwww.facebook.com\nno@spam.org' | \
sudo openssl req -x509 -nodes -days 365 -newkey rsa:2048 \
-keyout /etc/certs/facebook.key \
-out /etc/certs/facebook.crt
And make it trusted in the local system.
# curl
sudo cp /etc/certs/*.crt /usr/local/share/ca-certificates/
sudo update-ca-certificates
# Google Chrome
sudo apt install libnss3-tools -y
certutil -A -t "C,," -n "FB" -d sql:$HOME/.pki/nssdb -i /etc/certs/facebook.crt
# Mozilla Firefox
#certutil -A -t "CP,," -n "FB" -d sql:`ls -1d $HOME/.mozilla/firefox/*.default | head -n 1` -i /etc/certs/facebook.crt
Now run the web server using this certificate.
var fs = require('fs')
var https = require('https')
var express = require('express')
var options = {
key: fs.readFileSync(`/etc/certs/${process.argv[2]}.key`),
cert: fs.readFileSync(`/etc/certs/${process.argv[2]}.crt`)
}
var app = express()
app.use((req, res) => res.send(`<h1>hacked</h1>`))
https.createServer(options, app).listen(443)
Switch to the server
echo 127.0.0.1 www.facebook.com | sudo tee -a /etc/hosts
sudo node server.js facebook
Let’s see what happened
$ curl https://www.facebook.com
<h1>hacked</h1>
Great. curl validates the certificate.
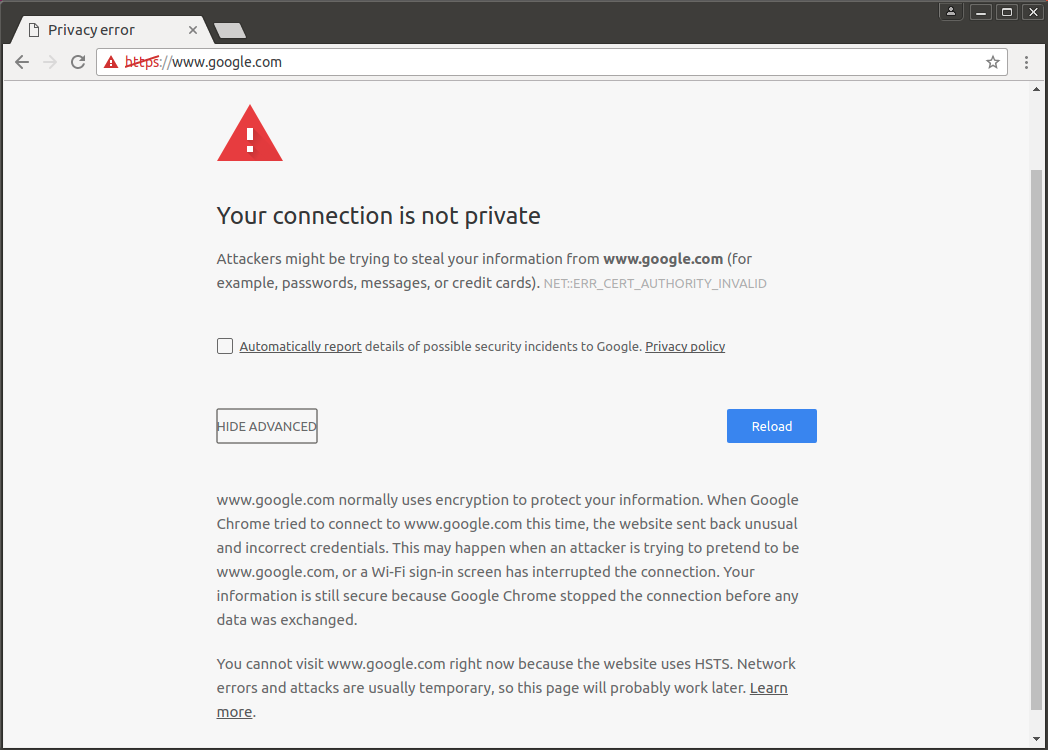
So as I already went to Facebook and Google Chrome has seen its headers, it should report the attack but to allow the page, right?

Nope. Keys are not checked because of local root certificate [Public key pinning bypassed]. This is interesting…
Well, and what about www.google.com?
echo -e 'US\nCA\nSF\nGoogle\nXX\nwww.google.com\nno@spam.org' | \
sudo openssl req -x509 -nodes -days 365 -newkey rsa:2048 \
-keyout /etc/certs/google.key \
-out /etc/certs/google.crt
sudo cp /etc/certs/*.crt /usr/local/share/ca-certificates/
sudo update-ca-certificates
certutil -A -t "C,," -n "Google" -d sql:$HOME/.pki/nssdb -i /etc/certs/google.crt
echo 127.0.0.1 www.google.com | sudo tee -a /etc/hosts
sudo node server.js google
The same result. I think this is a feature.
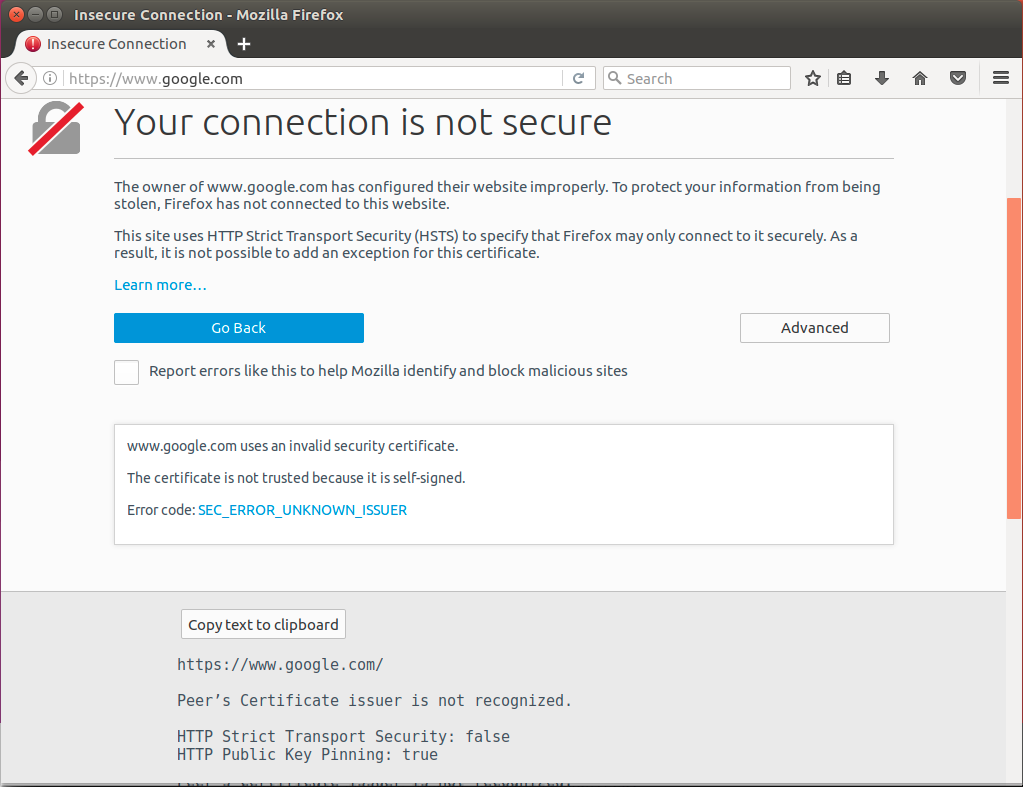
But in any case, if you do not add these certificates to the local store, open websites will not work because the option to continue with an insecure connection in Chrome or add an exception in Firefox will not.
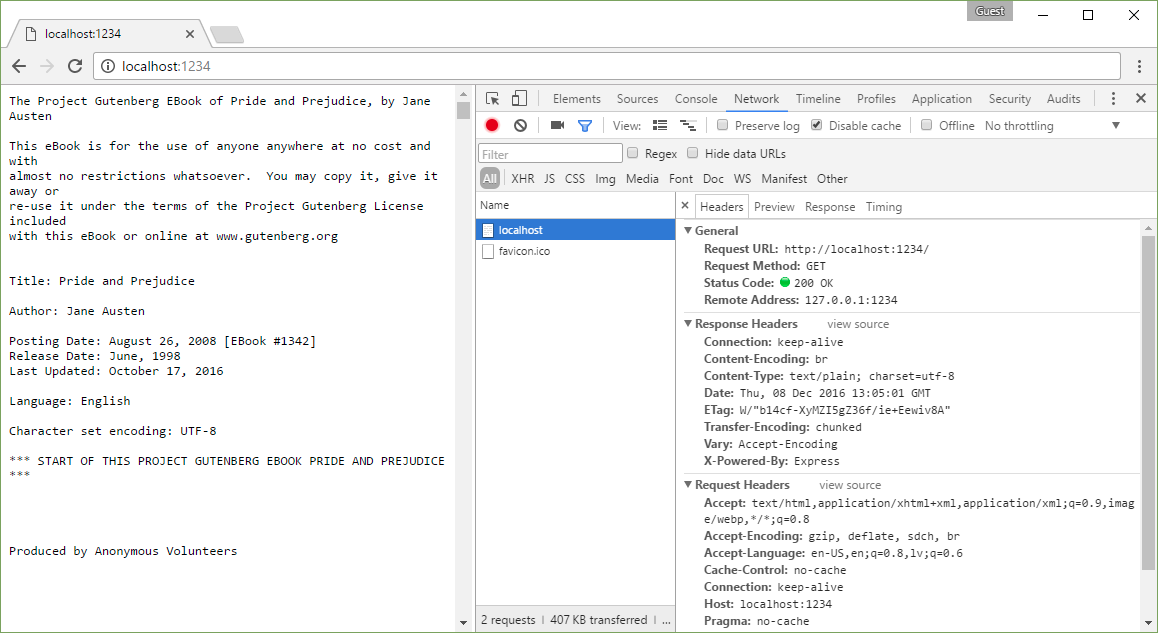
Content-Encoding: br
Data is compressed with Brotli.
The algorithm promises better compression than gzip and comparable speed unzipping. Supports Google Chrome.
Of course, there is a module for in node.js.
var shrinkRay = require('shrink-ray')
var request = require('request')
var express = require('express')
request('https://www.gutenberg.org/files/1342/1342-0.txt', (err, res, text) => {
if (err) throw new Error(err)
var app = express()
app.use(shrinkRay())
app.use((req, res) => res.header('content-type', 'text/plain').send(text))
app.listen(1234)
})
Original size: 700 KB
Brotli: 204 KB
Gzip: 241 KB
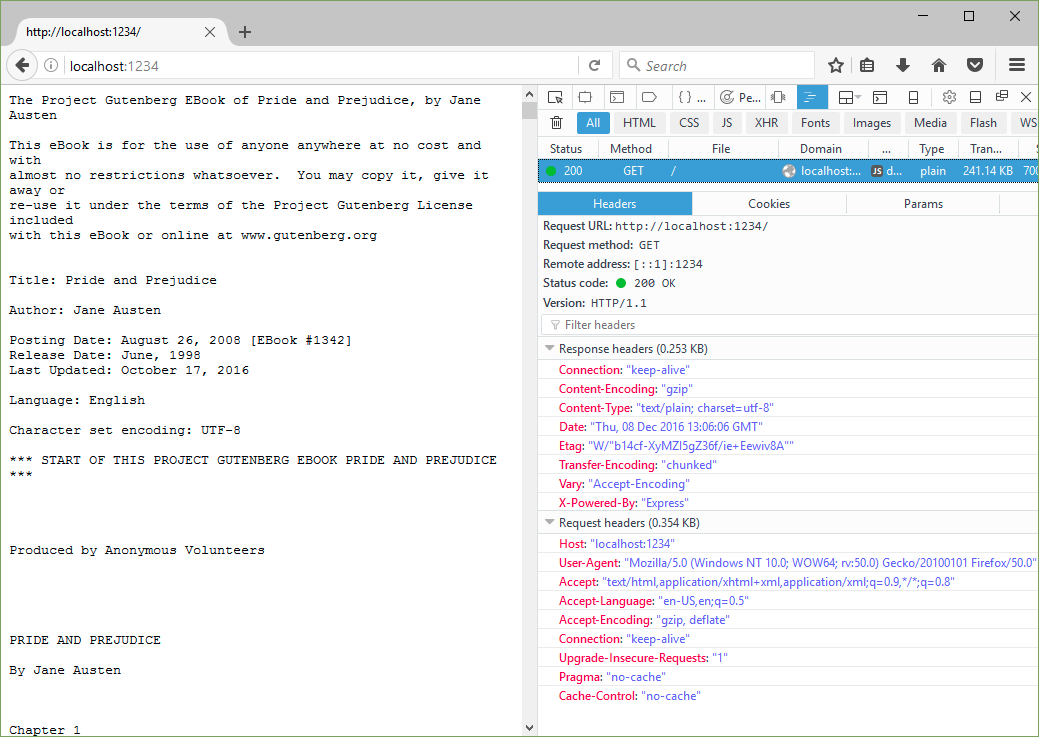
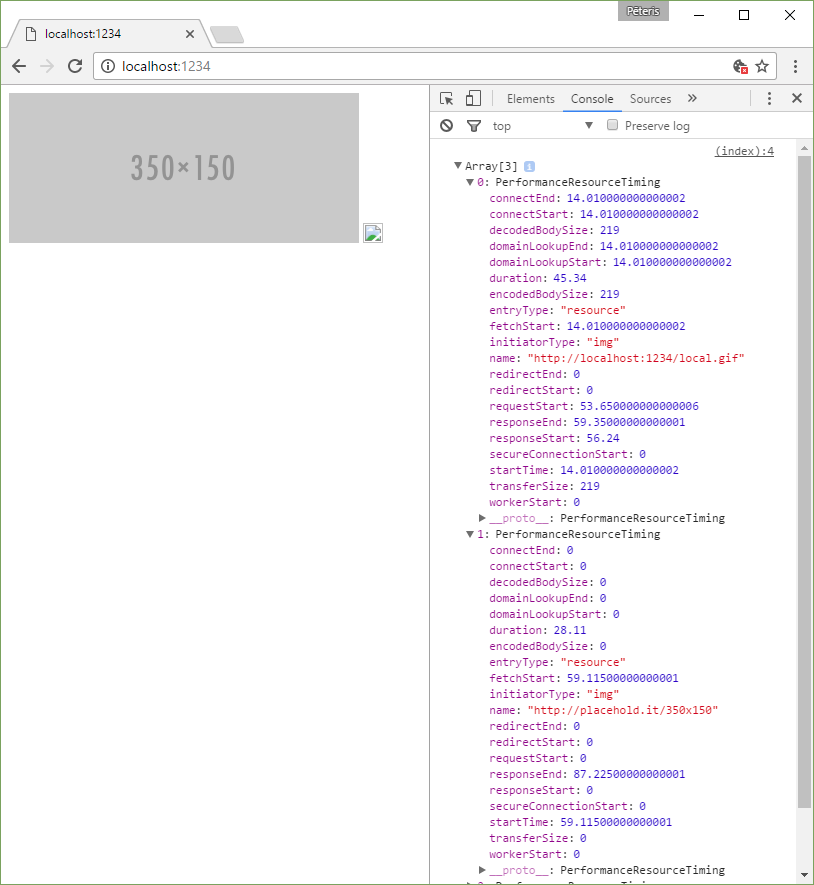
Timing-Allow-Origin
Using the Resource Timing API, you can find out how much time took the processing of resources on the page.
Because the information of load-time may be used to determine whether the user visited the page before this (paying attention to the fact that resources can be cached), a standard is considered to be vulnerable, if you give this information to any hosts.
<script>
setTimeout(function() {
console.log(window.performance.getEntriesByType('resource'))
}, 1000)
</script>
<img src="http://placehold.it/350x150">
<img src="/local.gif">
It seems that if you do not specify Timing-Allow-Origin, then get detailed information about the time of the operations (the search domain, for example) is possible only for resources with one source.
You can use this:
- Timing-Allow-Origin: *
- Timing-Allow-Origin: http://foo.com http://bar.com
Alt-Svc
The Alternative Services allow resources to be in different parts of the network and access to them can be obtained using different configurations of the protocol.
This is used in Google:
- alt-svc: quic=”:443″; ma=2592000; v=”36,35,34″
This means that the browser, if it wish, can use the QUIC, it is HTTP over UDP, over port 443 the next 30 days (ma = 2592000 seconds, or 720 hours, i.e. 30 days). I have no idea what means the parameter v, version?
P3P
Below are some P3P headers that I have seen:
- P3P: CP=«This is not a P3P policy! See support.google.com/accounts/answer/151657?hl=en for more info.»
- P3P: CP=«Facebook does not have a P3P policy. Learn why here: fb.me/p3p»
Some browsers require that cookies of third parties supported the P3P protocol for designation of confidentiality measures.
The organization, founded P3P, the world wide web Consortium (W3C) halted work on the protocol a few years ago due to the fact that modern browsers don’t end up to support protocol. As a result, P3P is outdated and does not include technologies that are now used in a network, so most sites do not support P3P.
I didn’t go too far, but apparently the header is needed for IE8 to accept cookies from third parties.
For example, if IE privacy settings are high, then all cookies from sites that do not have a compact privacy policy will be blocked, but those who have headlines similar to the above, will not be blocked.
Which of the following HTTP headers You use in projects?
X-XSS-Protection
X-Frame-Options
X-Content-Type-Options
Content-Security-Policy
Strict-Transport-Security
Public-Key-Pins
Content-Encoding
Timing-Allow-Origin
Alt-Svc
P3P
Other
This text is a translation of the article “Экзотичные заголовки HTTP” published by @A3a on habrahabr.ru.
About the CleanTalk service
CleanTalk is a cloud service to protect websites from spambots. CleanTalk uses protection methods that are invisible to the visitors of the website. This allows you to abandon the methods of protection that require the user to prove that he is a human (captcha, question-answer etc.).
Leave a Reply