Latest Articles

How AI Helps Speed Up Web Application Development
Web application development is not only about writing new code. A large part of daily work involves understanding existing logic,…
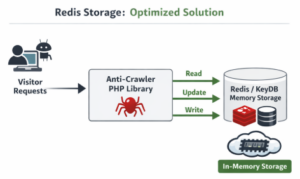
Reducing Disk Load in High-Traffic PHP Applications: Switching from SQLite to Redis for Anti-Crawler Storage
Automated crawlers and scraping bots are a growing problem for modern websites. While search engine bots are useful, many other…

How to Reduce Server Load by Simply Filtering Bad Traffic
When a website starts slowing down, many teams immediately think about scaling infrastructure: adding CPU, RAM, more servers, or optimizing…